The Abstraction Trap: When Policy Engines Lie
Policy engines promise a simple bargain: declare intent, and the platform does the wiring. When it works, you forget the hardware exists. When it doesn't, the hardware still has state—and now you're debugging it through a UI.
Outcome: Identity bindings reset, profiles re-applied, and failover validated against measured loss targets.
At a glanceGoal: Deploy a VDI cluster for a large institution using Cisco UCS and vSphere 8.Constraint: Zero downtime migration from legacy hardware.Reality: The "automated" tools failed at every critical juncture.
Engineering standards used
- Reversibility required for any migration step.
- Recovery paths documented before remediation (especially for policy engines).
- Failover tested and measured before acceptance.
- Version gaps treated as transfer risk, not an edge case.
- Automation verified at the hardware edge, not just in the UI.
1) When Logic Fights Physics
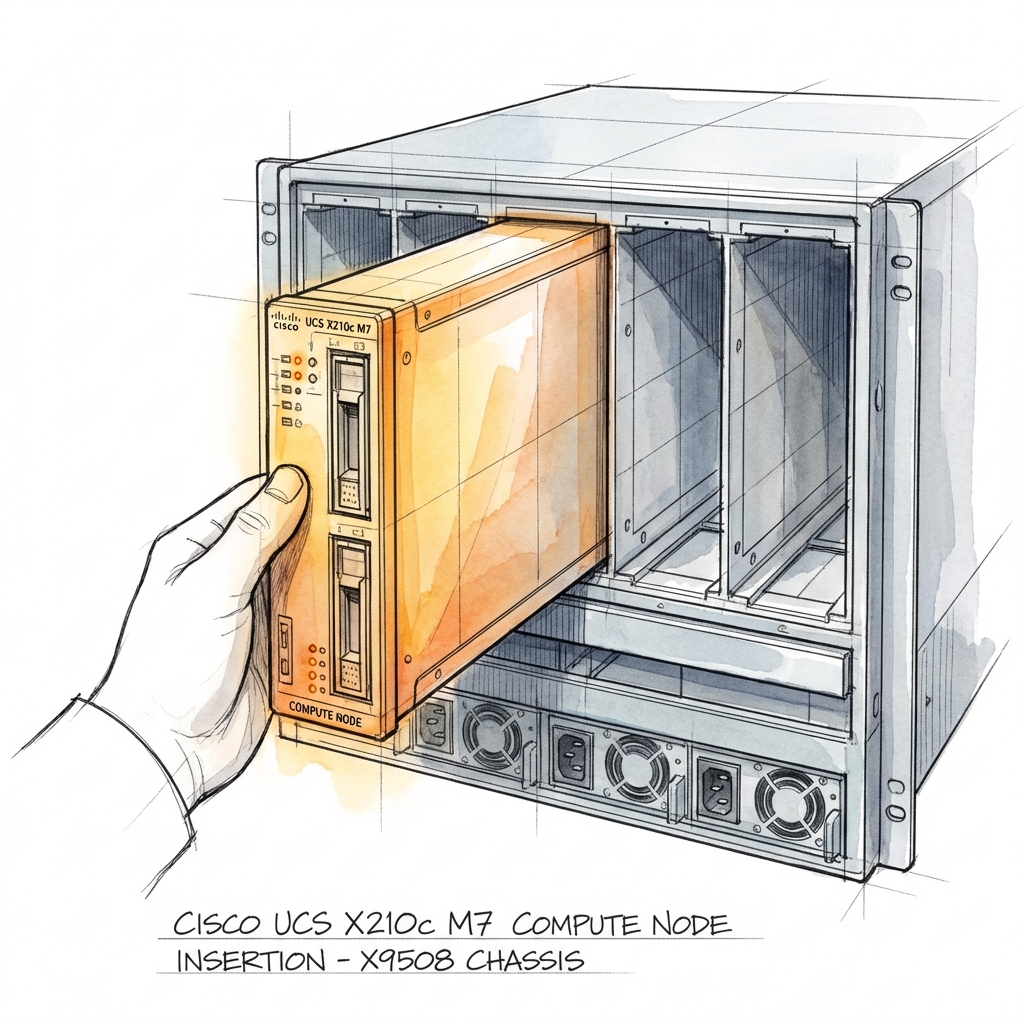
Cisco Intersight is designed to be the "brain" of the data center. It pushes policies to hardware so you don't have to configure servers manually.
In this deployment, the brain got confused in two ways:
First: the blades couldn't reliably reach or validate install media through the "automated" workflow. Once management networking was corrected, reachability snapped into place and the automated path became possible again.
Second: the policy engine refused to apply server profiles, flagging interfaces as having "No MAC Address" despite address pools being available. The system was stuck in a stale state—holding onto an identity that no longer matched the declared configuration.
The fix was not "try again harder." We forced a controlled reset: a temporary "dummy" profile to clear existing vNIC definitions and identity bindings, then re-applied the derived base templates.
Takeaway: Abstraction doesn't remove state. It just hides it—until it doesn't.
2) We Don't Gamble With Data
The industry default for migrating workloads between clusters is "magic button" migration. When it works, it's elegant. When it fails mid-transfer, it can leave partially moved data and an inconsistent inventory.
We chose the boring path instead. We attached the new storage to the old environment and moved VM data at the storage layer first. Only after the data was confirmed did we transition compute ownership.
Takeaway: A reversible migration plan is faster than a failed shortcut.
3) The 60-Second "Blip"
We built a redundant fabric: A side and B side, designed for instant failover. In testing, it wasn't.
During a controlled failover event, traffic went dark for roughly a minute. The culprit wasn't the UCS hardware—it was the upstream switching behavior: convergence and edge-port configuration that treated legitimate failover like a suspicious new topology.
We didn't sign off until failover was measured, repeated, and improved. The acceptance target was: a single dropped ping during failover.
Takeaway: Redundancy is not a checkbox. Redundancy is measured loss.
Engineering PrincipleVerification lives at the hardware edge. Document recovery paths for policy failures, and test redundancy with measured loss—not assumptions.